I wanted to explore a text based deformation that would allow me to dig into the soundtrack, in particular the dialogue, but do so in a way that removed as much of my own agency from the process as possible. This involved jumping through some hoops but here’s what I ended up with. I grabbed a subtitle (.srt) file for Se7en online (there are plenty of sources out there). Opening it in Notepad (Windows) I searched for all the lines that featured a particular word (in this case ‘sin’). The result was 11 lines which I saved as a new .srt file.
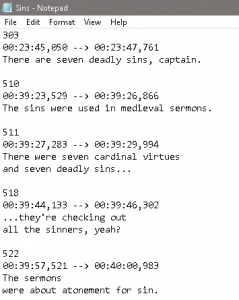
The next bit of the process wouldn’t have been possible without this handy Subtitle converter from editingtools.io. It took my new .srt and converted it to a Resolve compatible EDL (Edit Decision List). In Resolve I had a session with the full film which I applied the EDL to. Resolve made all the cuts for me and all I had to do was line up the clips and export.
In this version then I have very little agency (aside from choosing the word to use). The cut locations and length of the clips is dictated by the subtitle file, and its interesting to see how/where these occur when they’re driven by a focus on readability rather than absolute sync.
Postscript. Not long after I finished this I became aware of Videogrep by Sam Lavigne (via Zach Whalen and Jason Mittell). It uses Python to create ‘automatic supercuts’. I am still trying to get it working on my system!